Admin workflow
A complete evidence production pipeline, not a one-off upload
The admin interface coordinates the local evidence factory behind the chatbot: source discovery, document
download, segmentation, Markdown conversion, structured sidecar generation, vector and lexical indexing,
citation previews, quality checks, and deployment sync all sit in one workflow.
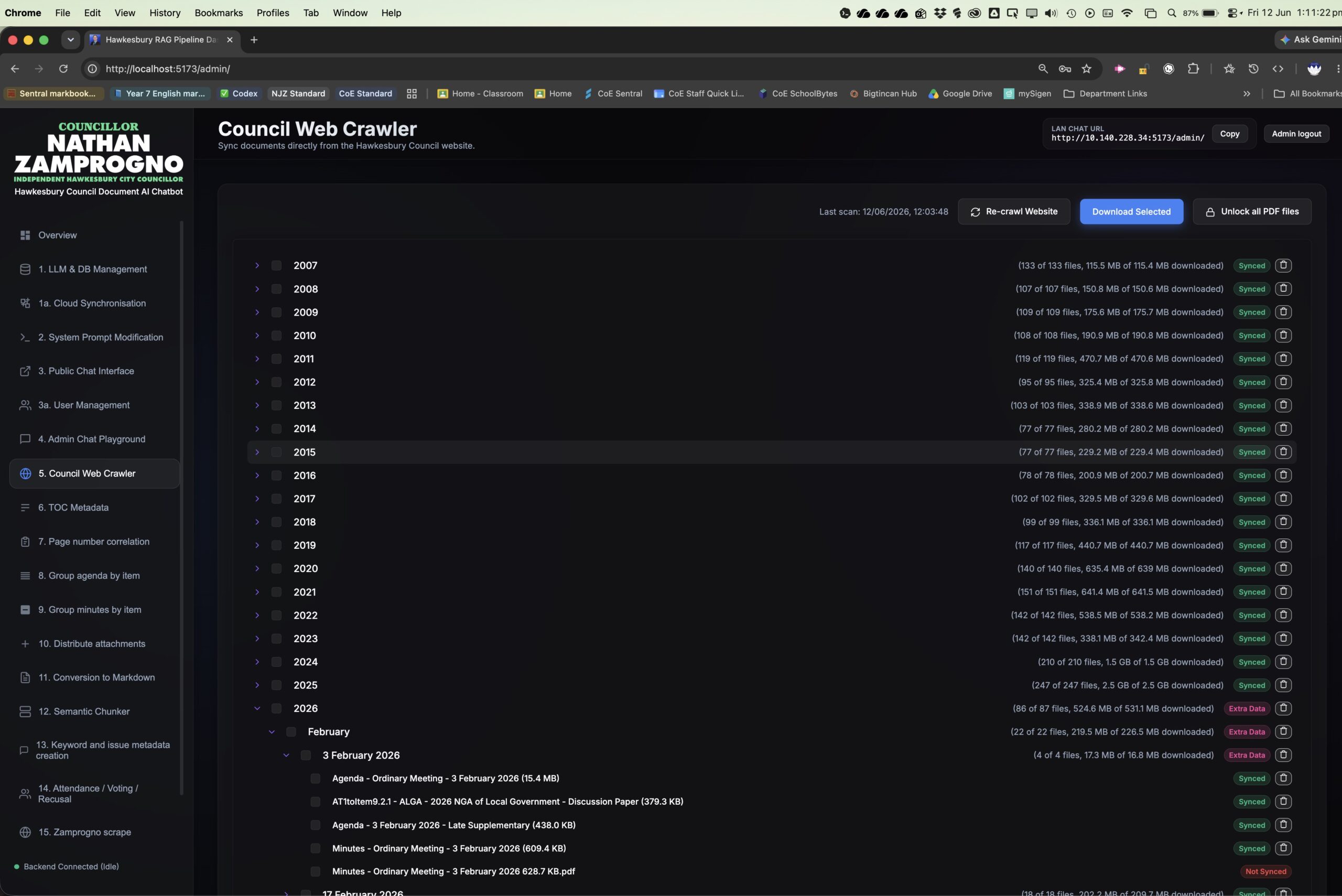
The workflow starts by scraping configured source websites, including Council meeting repositories, Council
web corpuses, consultation and data sites, and Councillor Zamprogno's site. New and changed files are
downloaded, catalogued, and checked against prior metadata so repeat runs can skip unchanged material.
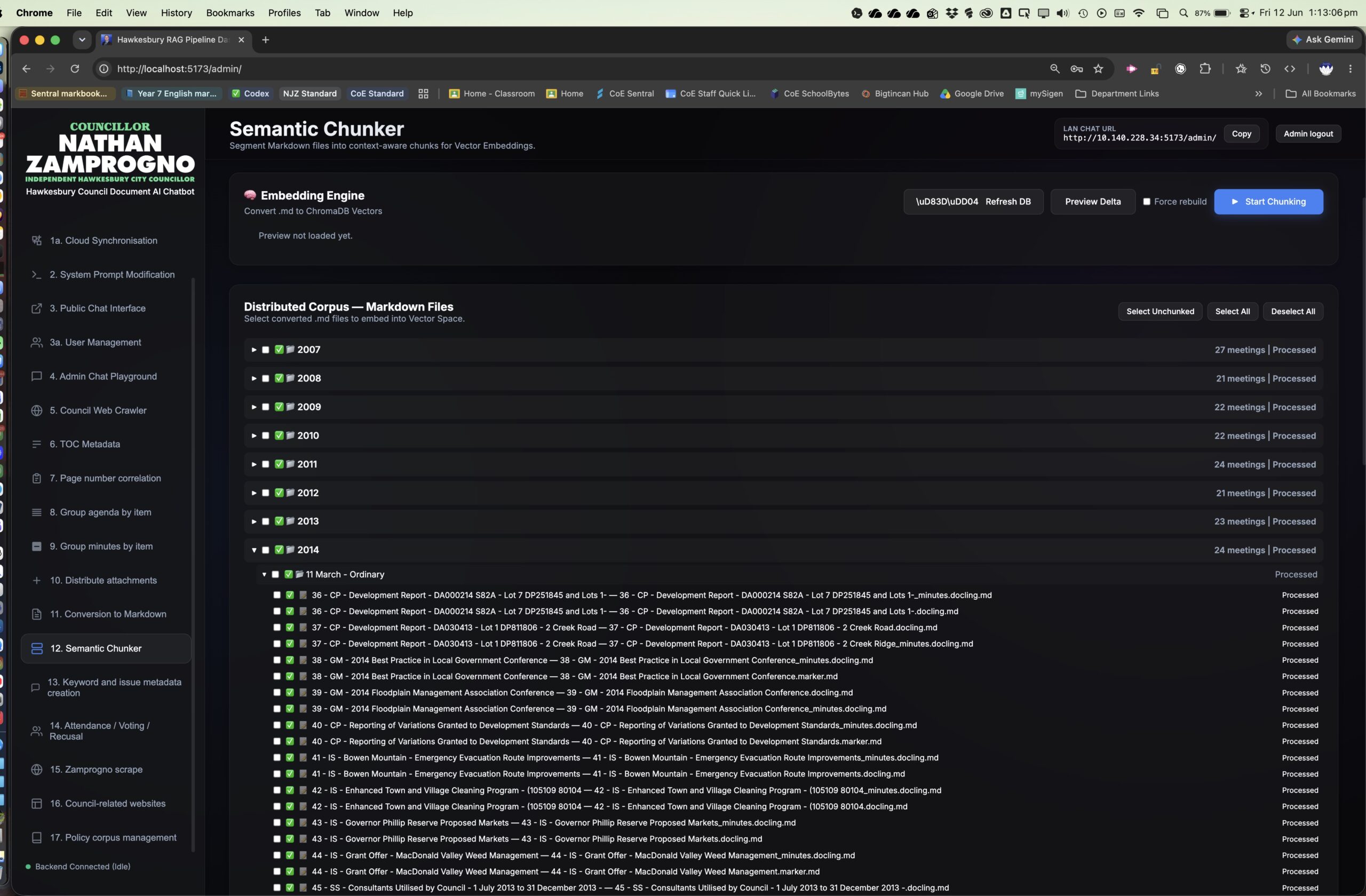
Meeting papers are then split into item-level records: agendas and minutes are segmented, attachments are
distributed to their parent items, page-number provenance is correlated, and PDF material is converted into
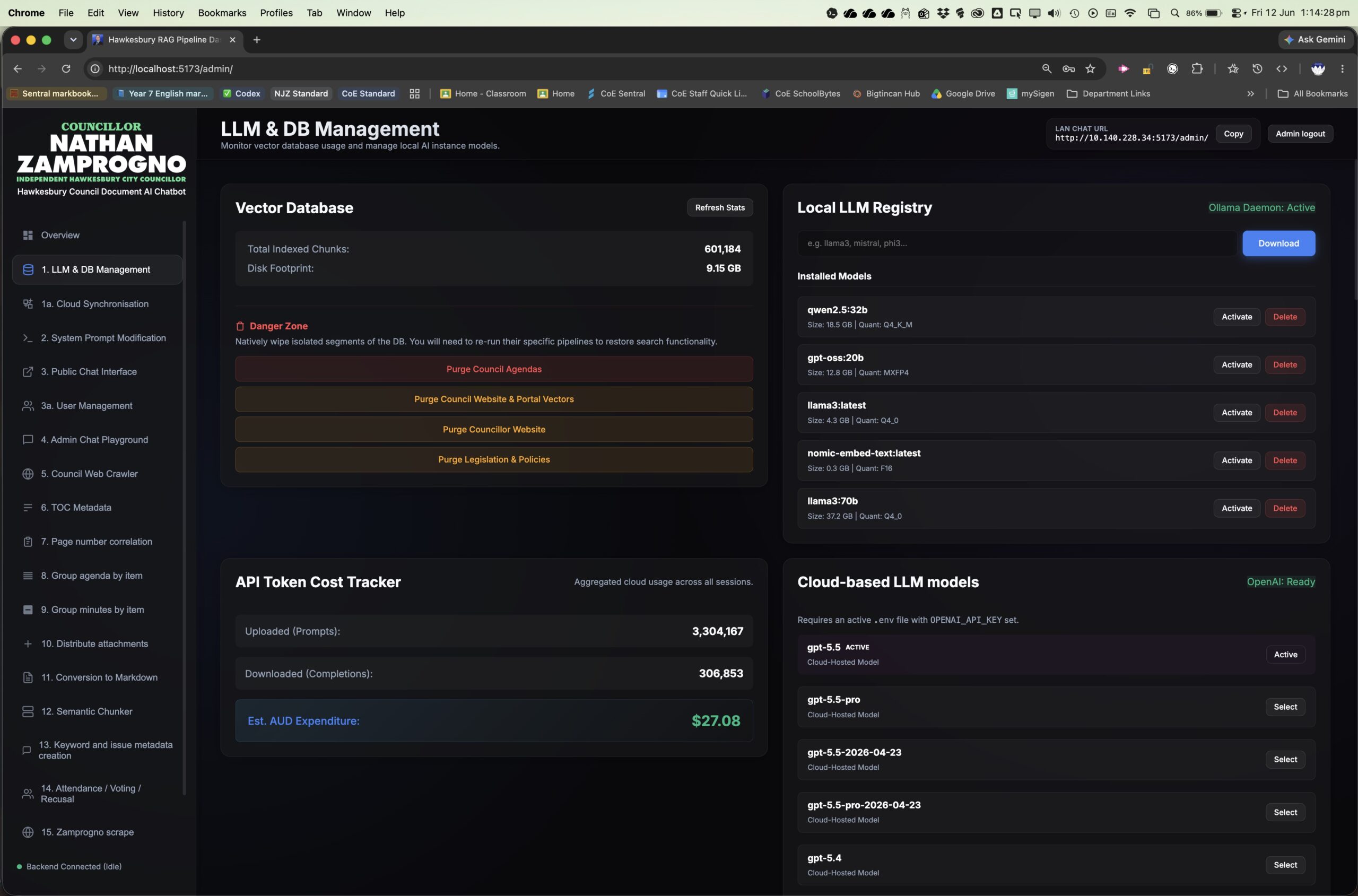
Markdown. Those Markdown files are chunked and embedded into sharded Chroma vector stores.
In parallel, preprocessing compiles JSON sidecars and global indexes for factual executors: votes,
attendance, conflicts, keywords, financial tables, rates, capital works, road-network subtotals, procurement,
grants, CouncilStats, and other recurring civic statistics. A generated SQLite FTS5 index mirrors the
searchable Chroma chunks, while preview workflows create safe first-page or website snapshots for citations.
Cloud synchronisation then compares and transfers the tested serving assets to the Oracle deployment.